IT is complex. Some even consider it to be more magic than reality. And with the ongoing evolutions and inventions, the complexity is not really going away. Sure, some IT areas are becoming easier to understand, but that is often offset with new areas being explored.
Companies and organizations that have a sizeable IT footprint generally see an increase in their infrastructure, regardless of how many rationalization initiatives that are started. Personally, I find it challenging, in a fun way, to keep up with the onslaught of new technologies and services that are onboarded in the infrastructure landscape that I'm responsible for.
But just understanding a technology isn't enough to deal with its position in the larger environment.
Complexity is a challenging beast
If someone were to attempt drawing out how the IT infrastructure of a larger IT environment looks like in reality, it would soon become very, very large and challenging to explain. Perhaps not chaotic, but definitely complicated.
One of the challenges is the amount of "something" that is out there. That can be the amount of devices you have, the amount of servers in the network, the amount of flows going through firewalls or gateways, the amount of processes running on a server, the amount of workstations and end user devices in use, the amount of containers running in the container platform, the amount of cloud platform instances that are active...
The "something" can even be less tangible than the previous examples such as the amount of projects that are being worked on in parallel or the amount of changes that are being prepared. However, that complexity is not one I'll deal with in this post.
Another challenge is the virtualized nature of IT infrastructure, which has a huge benefit for the organization and simplifies infrastructure services for its own consumers, but does make it more, well, complicated to deal with.
Virtual networks (vlans), virtual systems (hypervisors), virtual firewalls, virtual applications (with support for streaming desktop applications to the end user device without having the applications installed on that device), virtual storage environments, etc. are all wonderful technologies which allow for much more optimized resource usage, but does introduce a higher complexity of the infastructure at large.
To make sense of such larger structures, we start making abstractions of what we see, structuring it in a way that we can more easily explain, assess or analyze the environment and support changes properly. These abstract views do reflect reality, but only to a certain extend. Not every question that can be asked can be answered satisfactory with the same abstract view, but when it can, it is very effective.
Abstracting service complexity
In my day-to-day job, I'm responsible for the infrastructure of a reasonably large environment. With "responsible" I don't want to imply that I'm the one and only party involved of course - responsibilities are across a range of people and roles. I am accountable for the long-term strategy on infrastructure and the high-level infrastructure architecture and its offerings, but how that plays out is a collaborative aspect.
Because of this role, I do want to keep a close eye on all the services that we offer from infrastructure side of things. And hence, I am often confronted with the complexity mentioned earlier. To resolve this, I try to look at all infastructure services in an abstract way, and document it in the same way so that services are more easily explained.
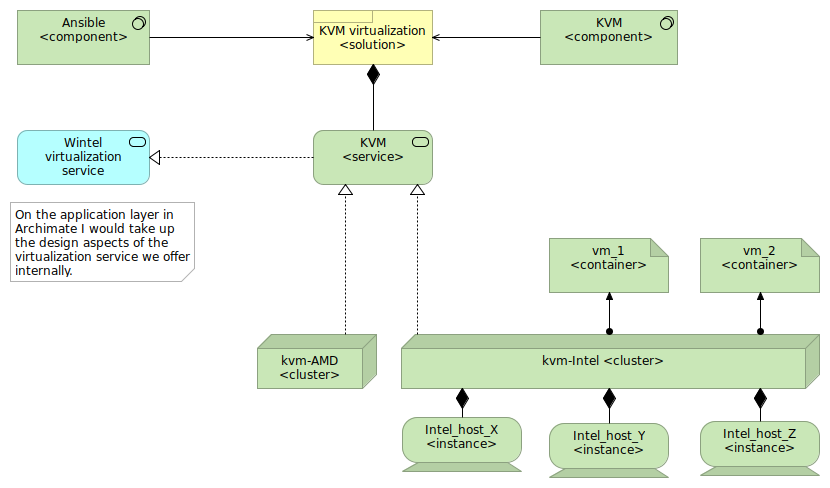
Figure 1 - A possible visualization of the abstraction model, here in Archimate
The abstraction I apply is the following:
- We start with components, building blocks that are used and which refer to a single product or technology out there. A specific Java product can be considered such a component, because by itself it hardly has any value.
- Components are put together to create a solution. This is something that is intended to provide value to the organization at large, and is the level at which something is documented, has an organizational entity responsible for it, etc. Solutions are not yet instantiated though. An example of a solution could be a Kafka-based pub/sub solution, or an OpenLDAP-based directory solution.
- Solutions are used to create services. A service is something that has an SLA attached to it. In most cases, the same solution is used to create multiple services. We can think of the Kafka-based pub/sub solution that has three services in the organization: a regular non-production one, a regular production one, and a highly available production service.
- Services are supported through one or more clusters. These are a way for teams to organize resources in support of a service. Some services might be supported by multiple clusters, for instance spread across different data centers. An OpenLDAP-based service might be supported by a single OpenLDAP cluster with native synchronization support spread across two data centers, or by two OpenLDAP clusters with a different synchronization mechanism between the two clusters.
- Clusters exist out of one or more instances. These are the actual deployed
technology processes that enable the cluster. In an OpenLDAP cluster, you
could have two master processes (
slapdprocesses) running, which are the instances within the cluster. - On top of the clusters, we enable containers (I call those containers, but they don't have anything to do with container technology like Docker containers). The containers are what the consumers are actually interested in. That could be an organization unit in an LDAP structure, a database within an RDBMS, a set of topics within a Kafka cluster, etc.
These are the basic abstractions I apply for most of the technologies, allowing me to easily make a good view on the environment. Let's look at a few examples here.
Example: Virtualization of Wintel systems
In a large, virtualized environment, you generally have a specific hypervisor software being used: be it RHV (Red Hat Virtualization) based upon KVM, Microsoft HyperV, VMWare vSphere or something else - the technology used is generally well known. That's one of the components being used, but that is far from the only component.
To better manage the virtualized environment the administration teams might use an orchestration engine like Ansible, Puppet or Saltstack. They might also have a component in use for automatically managing certificates and what not.
All these components are needed to build a full virtualization solution. For me, as an architect, knowing which components are used is useful for things like lifecycle management (which components are EOL, which components can be easily replaced with a different one versus components that are more lock-in oriented, etc.) or inventory management (which component is deployed where, which version is used), which supports things like vulnerability management (if we can map components to their Common Platform Enumeration (CPE) then we can easily see which vulnerabilities are reported through the Common Vulnerabilities and Exposure (CVE) reports).
The interaction between all these components creates a sensible solution, which is the virtualization solution. At this level, I'm mostly interested in the solution roadmap, the responsibilities and documentation associated with it, the costs, maturity of the offering within the organization, etc. It is also on the solution level that most architectural designs are made, and the best practices (and malpractices) are documented.
The virtualization solution itself is then instantiated within the organization to create one or more services. These could be different services based on the environment (a lab/sandbox virtualization service with low to no SLA, a non-production one with standard SLA, a non-production one with specific disaster recovery requirements, a production one with standard SLA (and standard disaster recovery requirements), a high-performance production one, etc.
These services are mostly important for other architects, project leads or other stakeholders that are going to make active use of the virtualization services - the different services (which one could document as "service plans") make it more obvious on what the offering is, and what differentiation is supported.
Let's consider a production, standard SLA virtualization service. The system administrators of the virtualization environment might enable this service across multiple clusters. This could be for several reasons: this could be due to limits (maximum number of hosts per cluster), or because of particular resource requirements (different CPU architecture requirements - yes even with virtualization this is still a thing), or to make things manageable for the administrators in general.
While knowing which cluster an application is on is, in general, not that important, it can be very important when there are problems, or when limits are being reached. As an architect, I'm definitely interested in knowing why multiple clusters are made (what is the reasoning behind it) as it gives a good view on what the administrators are generally dealing with.
Within a cluster (to support the virtualization) you'll find multiple hosts. Often, a cluster is sized to be able to deal with one or two host fall-outs so that the virtual machines (which are hosted on the cluster - these are the "containers" that I spoke of) can be migrated to another host with only a short downtime as a consequence (if their main host crashed) or no downtime at all (if it is scheduled maintenance of the host). These hosts are the instances of the cluster.
By using this abstraction, I can "map" the virtualization environment in a way that I have a good enough view, without proclaiming to be anything more than an informed architect, on this setup to support my own work, and to be able to advice management on major investment requirements, challenges, strategic evolutions and more.
More than just documentation
While the above method is used for documenting the environment in which I work (and which works well for the size of the environment I have to deal with), it can be used for simplifying management of the technologies as well. This level of abstraction can easily be used in environments that push self-servicing forward.
Let's take the Open Service Broker API as an example. This is an API that defines how to expose (infrastructure) services to consumers that can easily create (provision) and destroy (deprovision) their own services. Brokers that support the API will then automatically handle the service management. This model can easily be put in to support the previous abstraction.
Take the virtualization environment again. If we want to enable self-servicing on a virtualized environment, we can think of an offering where internal customers can create new virtual machines (provision) either based on a company-vetted template, or through an image (like with virtual appliances). The team that manages the virtualization environment has a number of services, which they describe in the service plans exposed by the API. An internal customer, when privisioning a virtual machine, is thus creating a "container" for the right service (based on their selected service plan) and on the right cluster (based upon the parameters that the internal customer passes along with the creation of its machine).
We can do the same with databases: a certain database solution (say PostgreSQL) has its own offerings (exposed through service plans linked to the service), and internal customers can create their own database ("container") on the right cluster through this API.
I personally have a few scripts that I use at home myself to quickly set up a certain technology, using the above abstraction level as the foundation. Rather than having to try and remember how to set up a multi-master OpenLDAP service, or a replicated Kafka setup, I have scripts that create this based upon this abstraction: the script parameters always use the service, cluster, instance and container terminology and underlyingly map this to the technology-specific approach.
It is my intention to also promote this abstraction usage within my work environment, as I believe it allows us to more easily explain what all the infrastructure is used for, but also to more easily get new employees known to our environment. But even if that isn't reached, the abstraction is a huge help for me to assess and understand the multitude of technologies that are out there, be it our mainframe setup, the SAN offerings, the network switching setup, the databases, messaging services, cloud landing zones, firewall setups, container platforms and more.